Top criteria to consider when choosing an appropriate scale for primary research in a PhD study
Top criteria to consider when choosing an appropriate scale for primary research in a PhD study
Collecting primary data for a PhD study is not trivial: a poor research instrument can lead to measurement error and raise concerns over the methodology of your study. Whether you decide to develop the scale yourself or adopt one from a previous study, there are several criteria you should consider when designing your survey. These criteria are rooted in the two key characteristics used to assess scale quality, namely reliability and validity.
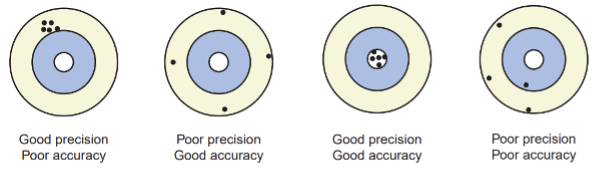
Validity and reliability resemble accuracy and precision, respectively. Source: Hulley, S. B., Cummings, S. R., Browner, W. S., Grady, D. G., and Newman, T. B. (2013). Designing Clinical Research. Philadelphia: Lippincott Williams and Wilkins.
To better understand the relationship between the criteria of validity and reliability, one can view reliability as precision and validity as accuracy. If a scale is unreliable, then survey estimates will have high variance. Similarly, an invalid scale would yield estimates that have large bias. The difficulty in choosing an appropriate scale for primary research in a PhD study is avoiding bias while reducing variance as much as possible. Although the concepts of variance and bias are rather intuitive, it can be challenging to assess whether scales are valid and reliable when designing a PhD study. This article explains how these concepts translate into specific criteria that researchers use to choose an appropriate scale for their studies.
Validity
As discussed above, you can think of validity as accuracy or unbiasedness of survey estimates. In other words, validity reflects the extent to which your scale measures what you actually intend to measure. In a qualitative PhD study, validity becomes a property of the instrument’s scores rather than of the instrument itself. As such, the top criteria for choosing a valid scale essentially correspond to hypotheses about the scale.
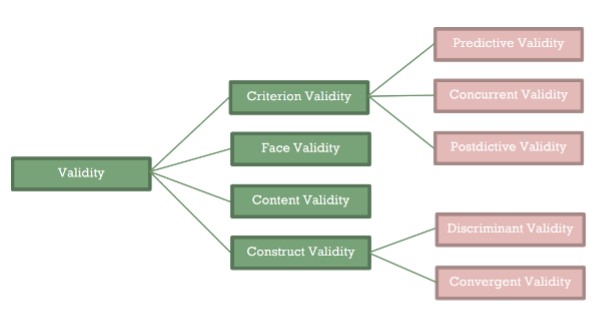
Subtypes Of Various Forms Of Validity Tests. Source: Taherdoost, H. (2016). Validity and reliability of the research instrument; how to test the validation of a questionnaire/survey in a research. International Journal of Academic Research in Management (IJARM), 5(3), pp.28-36.
Four types of validity are usually considered: criterion validity, face validity, content validity, and construct validity.
Criterion Validity
Among the top criteria of an appropriate scale for collecting primary research for a PhD study is criterion validity. Criterion, or concrete, validity is a broad term referring to the extent to which your scale is related to an outcome. Criterion validity focuses on how well a certain measure can predict an outcome for some other measure. In general, this type of validity is tested by examining empirical associations between test scores and scores for a specific criterion variable.
We can test criterion validity for different time frames which allows us to distinguish between predictive validity, concurrent validity, and postdictive validity. Predictive validity is meant to represent how well a test based on the scale predicts scores on a criterion measure. Put differently, a scale that possesses predictive validity should accurately predict what it is meant to predict. Usually, it is not easy to establish predictive validity since there may be faults of prediction in the criteria of success rather than the scale itself. One way to assess predictive validity is to carry out a long-term validity study. Since such studies require large sample sizes and may take a very long time to complete, establishing predictive validity of a scale developed for a PhD study from scratch may not always be feasible. In such cases, it might make more sense to rely on previous research in the field and use a scale for which predictive validity has already been established. Postdictive validity is similar to predictive validity with the only difference being that the criterion is now measured before the test rather than afterwards. Concurrent validity measures the extent to which the score on a scale is related to criteria collected at the same as the test being administered. Since both the scale items and the criteria test are administered simultaneously, it becomes more feasible to establish concurrent validity in a PhD study compared to predictive or postdictive validity.
Criterion validity is usually expressed as the coefficient of correlation between test scores of your scale and some criterion such as a performance metric or a score from another test. Correlation thresholds may greatly vary across research areas, so you should look into previous studies in your field to assess whether observed correlations allow you to establish criterion validity. However, the usual interpretation of the absolute value of correlation coefficients generally apply, with a coefficient of 0.1 indicating low validity, a coefficient of 0.3 suggesting medium validity, and a value of 0.5 indicating high validity.
Face Validity
While face validity is probably the weakest form of validity, it is nonetheless an important criterion for whether a scale is appropriate for collecting primary data for your PhD study. Face validity of a scale is a subjective judgement on whether the scale measures what it is actually supposed to measure. This type of validity measures the extent to which your scale appears to be relevant to test participants. Thus, a scale is required to be related to a specific construct from the perspective of non-experts. It is important for an appropriate scale to be valid on the face of it, since poor face validity could indicate issues with how your questionnaire appears to test participants in terms of readability, writing style, feasibility, clarity, and formatting.
Face validity can be measured by collecting responses on a dichotomous scale (‘Yes’/’No’), representing favourable and unfavourable judgements as categorical options. These responses can then be analysed by using e.g. the Cohen’s kappa coefficient to measure the agreement between test participants. General guidelines suggest that the magnitude of kappa of around 0.4 is considered to show fair agreement.
Content Validity
Another top criterion of an appropriate scale for a PhD study is content validity. Content validity is understood as the extent to which the questions on your instrument represent all possible questions that could be asked about the concept being measured. A scale with high content validity would have items that represent more of the domain of the concept. At the same time, if your scale has poor content validity, it may be missing some standard questions or be too narrow in the context of your field of study. Content validity is similar to face validity in the sense that subjective judgement is used to establish it. A literature review is first used to develop the scale, and a panel of experts is employed to determine whether the scale adequately covers the field of study.
A popular method for assessing content validity is Lawshe’s content validity ratio (CVR). The CVR is just a linear transformation of the extent of agreement across panels. There exist guidelines on the critical threshold CVR values (which depend on the number of panel members) on whether to retain or to eliminate an item.
Construct Validity
The final validity-based criterion of an appropriate scale for a PhD study is construct validity. Construct validity stands for the ability of your scale to measure an abstract concept or a construct. Construct validity can be viewed as the extent to which scores on your test can be explained by the explanatory construct of the underlying theory. Analysis of construct validity requires you to consider relationships of test scores with the variables that you intended to assess as well as those variables that have no relationship to the construct. What construct validity is intended to measure is how well you operationalised the construct. Typically, two components of construct validity are considered: convergent validity and discriminant validity.
Convergent validity is the extent to which measures of constructs that should be related are, in fact, related. Several methods for testing convergent validity have been used. For example, factor analysis can be employed to determine whether items load above some minimum recommend threshold (usually 0.40). Alternatively, simple correlation coefficients could be calculated, with the usual thresholds used to determine whether constructs are indeed related.
Discriminant, or divergent, validity refers to the degree to which some latent variable discriminates from other latent variables. In other words, discriminant validity means that the latent variable accounts for more variance than can be associated with other constructs or unmeasured influences and measurement error. If you fail to establish discriminant validity for some of your latent variables, this could imply that these variables are related to constructs to which they should not be related. For example, this may happen if your scale includes multiple constructs that are essentially measuring the same thing.
Several approaches exist for assessing discriminant validity. The Fornell-Larcker criterion requires the square root of the average variance extracted (AVE) of a construct to exceed correlations between the construct and other latent variables. The Campbell-Fiske criterion requires the scaled correlation between two constructs to not exceed 0.7. For the heterotrait–monotrait (HTMT) ratio method, the HTMT threshold is 0.9.
Reliability
While establishing validity of your scale should ensure that there is no significant bias stemming from the scale’s design, it is still possible that survey estimates have large variability. As such, an equally important criterion for an appropriate scale for a PhD study is reliability. Reliability refers to the degree to which measuring some phenomenon yields consistent and stable results. If the scale for your primary research is reliable, then repeated measurements should provide similar results. Issues with reliability are typically rooted in subjectivity. Indeed, if you require primary data collection for your PhD study, there is a concern that subjectivity may lead to researcher bias. However, there is a similar concern regarding the subjectivity of the test participants. If the test directions are ambiguous or if the questions are not clearly stated, the scale may become less reliable.
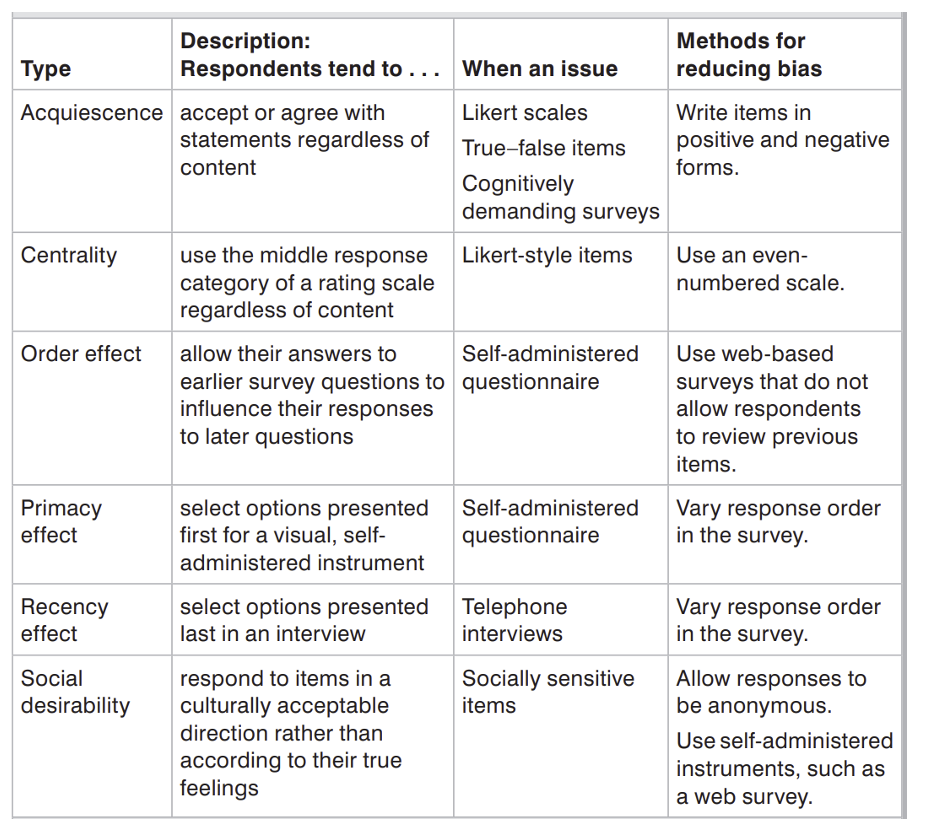
Types of Response Bias. From Johnson, R. L., and Morgan, G. B. (2016). Survey Scales: A Guide to Development, Analysis, and Reporting. New York: The Guilford Press.
Two major types of reliability can be considered: internal consistency, and stability.
Internal consistency
Internal consistency is meant to assess whether items are measuring the same construct. We can consider two forms of internal consistency reliability: inter-item consistency and split-half reliability. Inter-item consistency is the extent to which the information is being collected in a consistent manner. The most widely-used measure is Cronbach’s alpha. While no universal rules exist regarding thresholds for alpha, researchers usually note the minimum value of 0.7. However, this value may be accepted to be lower (e.g. 0.6 or above) if your study is a pilot study or an exploratory study. Split-half reliability compares one half of the results to the other half. A simple correlation coefficient is used to measure split-half reliability. A variety of alternative methods for measuring internal consistency exist, including the Rulon method, the Guttman formula, and the Kuder-Richardson formula.
Stability
Stability is understood as the robustness of a measure over time to respondents and uncontrolled testing conditions. If you were to administer the test to the same person after some time, how much would that person’s score change? A perfectly stable measure should yield the exact same scores. There are two commonly used approaches for assessing stability: test-retest reliability and parallel-form reliability. Test-retest reliability reflects the external consistency of a test. This type of reliability allows for estimate how much the score varies from one testing session to another. The test-retest coefficient is estimated by repeating the same measure a second time and calculating the correlation coefficient between two sets of data, with values above 0.7 usually deemed acceptable.
The parallel-forms reliability is measured by administering different versions of the test to the same individuals. Correlating the scores from the two sets of data produces the coefficient of parallel-forms reliability, with the usual thresholds for correlation coefficients being applicable.
Other considerations
If you cannot establish validity or reliability of your scale for primary research in a PhD study, it might not be immediately obvious what you could do to improve your instrument design. In this case, it can be valuable to consider non-statistical criteria and guidelines for developing a scale. For example, simplicity of item wording may help enhance reliability of your scale. You should avoid ‘double-barrelled’ items, items that depend on familiarity with little-known facts, and vague items. Make sure that you have accounted for possible differences in the cultural context when adapting a scale from previous studies. It can be a good idea to avoid ‘response sets’ (the tendency of individuals to respond for reasons other than the content of the items) by using forced-choice items. By following the general guidelines from methodology literature, you should be able to achieve levels of validity and reliability that are appropriate for primary research in a PhD study. If you still feel concerned about your primary research, you can always get PhD research help from our professional dissertation writers to make sure your scale is appropriate, valid, and reliable.